For 25 chapters, you've been the client. You've consumed APIs from OpenWeather, NewsAPI, Spotify, GitHub. You've sent HTTP requests, parsed JSON responses, handled authentication flows, and built applications on top of external data sources.
Basically, You've written code that calls requests.get() and processes what comes back.
Now you're ready for the flip side: you're going to be the API. You're going to build the system that receives those HTTP requests, validates authentication, enforces rate limits, queries databases, and returns JSON responses. You're going to create the endpoints that other developers integrate with. This isn't just a technical skill change. It's a professional identity shift.
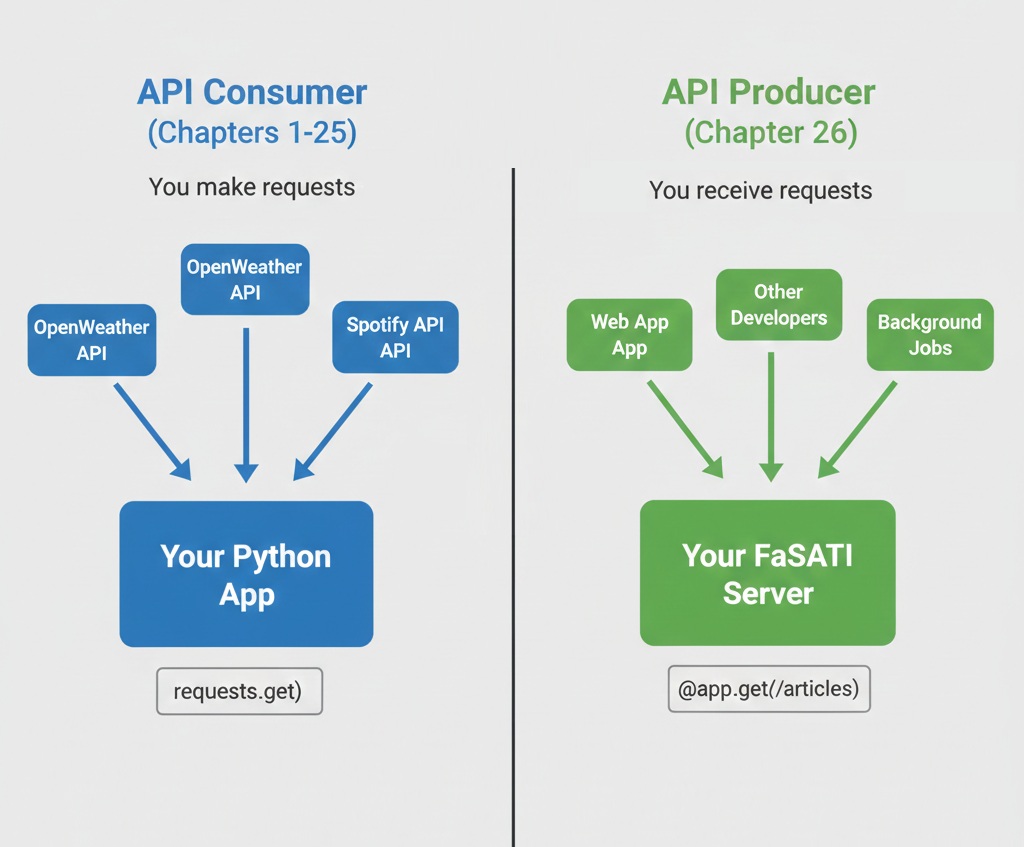
This chapter teaches you to build production-grade REST APIs using FastAPI, PostgreSQL, and professional patterns for authentication, rate limiting, and error handling.
You'll create a News Aggregator API that consolidates multiple news sources into one clean interface, demonstrating the exact patterns companies use to expose their data to developers. By the end, you'll have a deployed API with automatic documentation, secure authentication, and comprehensive test coverage—ready to show recruiters as proof you understand both sides of the API equation.
The API Producer Mindset
As a consumer, you think: "How do I call this API? What parameters does it accept? How do I handle errors?" These are client-side concerns. As a producer, the questions change completely.
What if someone makes 1,000 requests per second?
Without rate limiting, a single user can exhaust your database connections, spike your hosting costs, or crash your server. As a consumer, you never worried about this. As a producer, it's a critical design decision from day one.
How do you prevent abuse while staying accessible?
Every API needs authentication to track usage and prevent unauthorized access. But too much friction discourages adoption. Professional APIs balance security with developer experience—making authentication simple but secure.
How do you version your API without breaking existing users?
You'll improve your API over time, adding features and optimizing responses. But users depend on your current endpoints. Changing response formats breaks their code. Professional APIs version endpoints so improvements don't destroy existing integrations.
How do you help developers understand what went wrong?
As a consumer, you've seen generic 500 errors that provided no useful information. Frustrating. As a producer, you control what error messages users see. Good APIs return clear error messages, proper status codes, and actionable guidance. Poor APIs leave developers guessing.
Building APIs means other people's applications depend on your code. If your API goes down, their services break. If you change response formats without warning, you break production systems. If your error messages are unclear, you waste hours of other developers' time.
This responsibility shapes how you design, build, test, and deploy APIs. Professional API development isn't just writing code that works for you. It's building systems that work reliably for everyone who integrates with them, with clear documentation, predictable behavior, and graceful degradation when things go wrong.
What You'll Build: The News Aggregator API
Following news means checking multiple sources. Tech news from Hacker News, world events from The Guardian, breaking stories from NewsAPI. Each source has different API formats, different authentication requirements, different rate limits, and different response structures. Developers who want comprehensive news coverage must integrate with three, four, or five separate APIs.
Your News Aggregator API solves this problem. It aggregates articles from NewsAPI and The Guardian into one unified interface. Developers get one API key, one consistent response format, and access to multiple news sources through clean REST endpoints. Behind the scenes, your API handles the complexity: fetching from multiple sources, normalizing different response formats, caching results in PostgreSQL, and enforcing rate limits.
For consumers, the interface is simple:
GET /articles?category=technology&source=newsapi
Authorization: Bearer YOUR_API_KEY
Response:
{
"articles": [
{
"id": "news_12345",
"title": "AI Breakthrough in Medical Imaging",
"description": "Researchers develop algorithm...",
"url": "https://example.com/article",
"source": "newsapi",
"category": "technology",
"published_at": "2024-12-09T10:30:00Z"
}
],
"total": 42,
"page": 1
}For you as the builder, the system demonstrates professional patterns:
Multi-source integration: Your API fetches from NewsAPI and Guardian, handles their different authentication methods, normalizes responses, and merges results into one clean format.
Database caching: Articles are stored in PostgreSQL with timestamps. Recent requests return cached data instantly. Stale cache triggers fresh API calls. This reduces external API usage and improves response times.
API key authentication: Users generate API keys through an admin endpoint. Keys are hashed before storage (like passwords). Every request validates the API key using middleware before processing.
Rate limiting: Each API key has usage limits tracked in PostgreSQL. Exceed your limit and you get a 429 status code with clear messaging about when limits reset.
Automatic documentation: FastAPI generates interactive API docs at /docs. Developers can test endpoints directly in the browser, see request/response schemas, and understand authentication requirements without reading separate documentation.
This isn't a toy project. The News Aggregator API demonstrates real production patterns: authentication, rate limiting, database integration, external API orchestration, caching strategies, comprehensive error handling, and deployment. These are the exact skills companies need for backend API development.
When you show this to recruiters, you're demonstrating: "I understand how to build the systems that power modern applications. I've implemented authentication, handled rate limiting, integrated databases, and deployed production APIs." That's far more valuable than tutorial completion certificates.
By the end of this chapter, you'll have a deployed News Aggregator API with:
- Multi-source integration (NewsAPI + Guardian)
- API key authentication with secure hashing
- Rate limiting (100 requests/hour free tier)
- PostgreSQL caching for performance
- Automatic interactive documentation at /docs
- Comprehensive pytest test suite
- Live URL for your portfolio
Why FastAPI?
FastAPI is a Python framework for building high-performance APIs with built-in support for validation, documentation, and async.
Python has several frameworks for building APIs:
- Flask (simple but requires extensions for validation and docs)
- Django REST Framework (powerful but heavyweight)
- FastAPI (modern with built-in features for production APIs)
For this chapter, FastAPI is the clear choice.
Automatic OpenAPI documentation
Write your endpoints and FastAPI generates interactive documentation automatically at /docs. No separate documentation to maintain. No Swagger configuration files. The docs update automatically when you change code.
Built-in Pydantic validation
Define your request and response schemas using Python type hints. FastAPI automatically validates incoming data, generates clear error messages for invalid input, and provides type safety throughout your codebase. No manual validation code needed.
Async support for performance
FastAPI is built on modern async Python, allowing high-performance concurrent request handling. While this chapter uses synchronous code for clarity, you can add async support later when you need it.
Industry adoption
Microsoft, Uber, and Netflix use FastAPI in production. It's not an experimental framework—it's proven technology with active maintenance and strong community support.
Developer experience
FastAPI's automatic error messages, clear documentation, and Pydantic integration make debugging significantly easier than manual validation frameworks. When something goes wrong, you get specific, actionable error messages.
Flask is excellent for web applications with templates and server-side rendering. But for building APIs, FastAPI provides critical features out of the box that require multiple Flask extensions: automatic request validation, response serialization, OpenAPI documentation, and async support.
If you've built Flask apps (like the Music Time Machine dashboard in Chapters 17-18), you'll find FastAPI familiar but more specialized for API development. The core patterns transfer: routing, error handling, database integration. FastAPI just removes boilerplate and adds automatic documentation.
Learning Objectives
By the end of this chapter, you'll be able to:
- Design RESTful APIs following industry conventions for resource naming, HTTP methods, and status codes
- Build production-ready APIs with FastAPI, Pydantic validation, and automatic OpenAPI documentation
- Implement API key authentication with secure hashing and middleware-based validation
- Integrate PostgreSQL databases with APIs using SQLAlchemy for data persistence and caching
- Add rate limiting to prevent abuse and track API usage per key
- Test API endpoints comprehensively using pytest with authentication and database mocking
- Deploy authenticated APIs to production with environment-based configuration
- Create developer-friendly API documentation that makes your API easy to adopt
Chapter Roadmap
We'll build the News Aggregator API systematically, adding complexity progressively:
REST API Fundamentals
Learn REST principles, HTTP methods, status codes, and resource naming before writing any code. You'll design your API interface following industry conventions.
Your First FastAPI Application
Get FastAPI running with basic endpoints. You'll learn routing, path parameters, query parameters, and automatic documentation generation.
Database Integration
Connect PostgreSQL using SQLAlchemy. You'll define models, implement CRUD operations, and use connection pooling for production reliability.
API Key Authentication
Implement secure authentication with hashed keys and middleware validation. You'll generate keys, validate them on every request, and return proper 401 errors for unauthorized access.
Rate Limiting
Prevent abuse by tracking request counts per API key. You'll implement fixed-window rate limiting and return appropriate 429 status codes when limits are exceeded.
Building the News Aggregator
Bring everything together. You'll integrate NewsAPI and Guardian, implement caching, and create production-ready endpoints that aggregate multiple sources.
Testing Your API
Write comprehensive pytest tests covering authentication, rate limiting, database operations, and external API mocking.
Production Deployment
Deploy your API to Railway with environment-based configuration, proper secret management, and PostgreSQL database connection.
By Section 7, you'll have a complete, working API. Sections 8-9 polish it into a production-ready, portfolio-worthy project.
This chapter assumes you're comfortable with Python fundamentals, have used APIs as a consumer (Chapters 1-9), understand OAuth basics (Chapter 14), and have SQLite database experience (Chapter 15). PostgreSQL knowledge is helpful but not required—we'll introduce what you need.
Tooling: Examples use Python 3.10+, FastAPI, PostgreSQL, and SQLAlchemy.
The next section lays the conceptual foundation. Before writing any FastAPI code, you'll learn REST principles, HTTP methods, status codes, and resource naming conventions. Understanding these fundamentals ensures your API follows industry standards from the start.